هوش مصنوعی DeepSeek؛ چالش تازهای برای غولهای غربی در دنیای مدلهای زبانی
هوش مصنوعی DeepSeek، استارتاپ نوظهور اما بلندپرواز چینی، بهتازگی با رونمایی از مدل جدید خود با نام DeepSeek V3-0324 موجی از توجه و هیجان را در جامعه فناوری ایجاد کرده است. این مدل که در ادامه مسیر توسعه پرفرازونشیب DeepSeek ارائه شده، نشان میدهد که بازیگران آسیایی نیز با سرعتی خیرهکننده در حال نزدیک شدن به سطح تواناییهای شرکتهایی چون OpenAI (سازنده ChatGPT) و Anthropic (سازنده Claude) هستند.
معرفی غیرمنتظره DeepSeek V3-0324 و آغاز فصل جدیدی در رقابتهای هوش مصنوعی
مدل هوش مصنوعی DeepSeek V3-0324 برخلاف انتظارات عمومی، بدون پیشزمینه تبلیغاتی گسترده معرفی شد و همین عامل باعث شد نگاهها به عملکرد و تواناییهای فنی آن دوچندان شود. بر اساس گزارشهای اولیه، این مدل در زمینههایی چون کدنویسی پیشرفته، درک زبان طبیعی و پردازش متون عملکردی فراتر از حد انتظار از خود نشان داده است. در واقع، DeepSeek ادعا کرده که در برخی وظایف خاص حتی توانسته مدلهای غربی را پشت سر بگذارد.
بیشتر بدانید: نحوه استفاده ازDeepSeek-V3 و تفاوت آن با DeepSeek-R1 چیست؟
تست DeepSeek روی مکاستودیو M3 Ultra؛ بیش از ۲۰ توکن در ثانیه!
یک پژوهشگر مستقل در حوزه هوش مصنوعی، مدل DeepSeek V3 را روی دستگاه Mac Studio با پردازنده M3 Ultra آزمایش کرده و به عدد قابلتوجه بیش از ۲۰ توکن پردازش در هر ثانیه رسیده است. این رقم برای مدلهای حجیم زبان طبیعی بسیار چشمگیر است، هرچند باید در نظر داشت که مکاستودیو با برچسب قیمتی ۹۵۰۰ دلاری، یک سیستم فوقپیشرفته محسوب میشود و نمیتوان این نتایج را به تمام سختافزارهای بازار تعمیم داد. یکی از سوالات اصلی پیرامون هوش مصنوعی DeepSeek این است که آیا این عملکرد فوقالعاده روی سیستمهای متوسط و عمومی نیز قابلدستیابی است یا خیر؟ برای پاسخ قطعی به این سؤال، نیازمند بررسیهای گستردهتری هستیم.
جهش DeepSeek در معماری مدل با رویکرد Mixture of Experts (MoE)
یکی از برجستهترین ویژگیهای هوش مصنوعی DeepSeek در نسخه V3-0324، استفاده از معماری نوآورانه Mixture of Experts (ترکیب متخصصان) است. این رویکرد بهجای استفاده از تمام پارامترهای مدل بهصورت همزمان، تنها بخشی از پارامترها را برای هر وظیفه فعال میکند. بهطور مشخص، مدل DeepSeek دارای ۶۸۵ میلیارد پارامتر است، اما در هر درخواست فقط حدود ۳۷ میلیارد پارامتر به کار گرفته میشوند.
این تکنیک باعث میشود بهرهوری پردازشی بهشدت افزایش یابد و در عین حال هزینههای محاسباتی به شکل چشمگیری کاهش پیدا کند. چنین مزیتی، DeepSeek را از بسیاری از مدلهای سنگینوزن آمریکایی متمایز میکند و میتواند تحولی مهم در رقابتهای تجاری مدلهای زبانی بزرگ باشد.
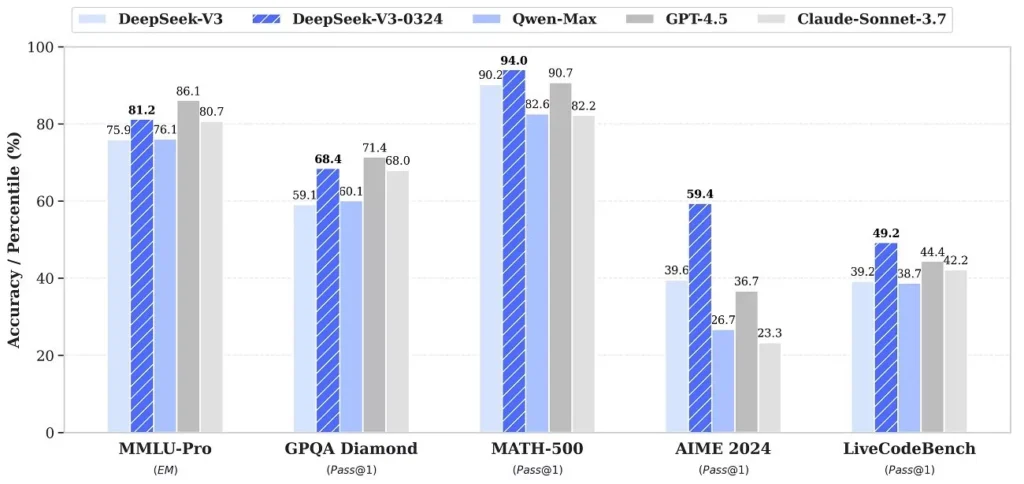
رقابت DeepSeek با OpenAI و Anthropic؛ واقعیت یا تبلیغ؟
در مقایسه با مدلهای معروفی همچون ChatGPT از OpenAI یا Claude از Anthropic، نسخه جدید DeepSeek نشان داده که فاصله فنی میان شرق و غرب در حوزه هوش مصنوعی در حال کاهش است. هرچند هنوز معیارهای جامعی برای سنجش کیفیت عملکرد مدلها در طیف وسیعی از وظایف وجود ندارد، اما DeepSeek با عملکرد قوی خود در حوزههای خاص مانند کدنویسی و تحلیل زبان طبیعی، توانسته خود را بهعنوان یک رقیب جدی معرفی کند.
جالبتر اینکه DeepSeek بهجای اتکا به تبلیغات گسترده، روی توسعه پیوسته و بهروزرسانیهای سریع تمرکز کرده است. نسخه اولیه DeepSeek V3 در دسامبر ۲۰۲۳ معرفی شد و تنها یک ماه بعد، مدل reasoning محور R1 نیز ارائه گردید. حالا با عرضه V3-0324 در ابتدای سال ۲۰۲۵، این استارتاپ چینی نشان داده که چرخه توسعه سریعی دارد.
بخوانید: 10 سایت برتر برای یادگیری هوش مصنوعی
مزایای رقابتی هوش مصنوعی DeepSeek: عملکرد قوی و قیمت مقرونبهصرفه
نکته مهمی که DeepSeek را از سایر بازیگران بازار متمایز میسازد، ترکیب عملکرد بالا با قیمت رقابتی است. حتی اگر این مدل در برخی معیارها کمی پایینتر از رقبای غربی باشد، اما قیمت پایینتر آن برای شرکتها، توسعهدهندگان و محققانی که به دنبال مدلهای بهینهتر هستند، گزینهای بسیار جذاب به شمار میرود.
جمعبندی: آیا DeepSeek آینده هوش مصنوعی را شکل خواهد داد؟
با توجه به روند سریع توسعه، عملکرد فنی قابلقبول، معماری هوشمندانه و استراتژی قیمتی جذاب، به نظر میرسد هوش مصنوعی DeepSeek یکی از جدیترین بازیگران جدید در صنعت مدلهای زبانی هوشمند باشد. گرچه هنوز راه درازی برای رسیدن به برتری مطلق باقی مانده، اما DeepSeek ثابت کرده که نهتنها یک استارتاپ ساده نیست، بلکه میتواند آینده هوش مصنوعی را تحت تأثیر قرار دهد.
بیشتر بدانید: چگونه DeepSeek با ۵ میلیون دلار صنعت هوش مصنوعی را متحول کرد و غولهای فناوری را به چالش کشید